LaunchBuddy (BETA)
powered by Experiment Nation
At most companies, the majority of features are launched without an A/B test. Ironically, those are often the very launches leadership wants to measure the impact of. Sound familiar?
That’s why we created LaunchBuddy: a pre- and post-launch analyzer for low-traffic sites that estimates the probability your new feature is actually an improvement.
All you need is your raw data in CSV form (1 file for the pre-launch data, another for the post-launch data, less than 20k rows each, ideally)
We’ll handle the rest.
How Do you use LaunchBuddy?
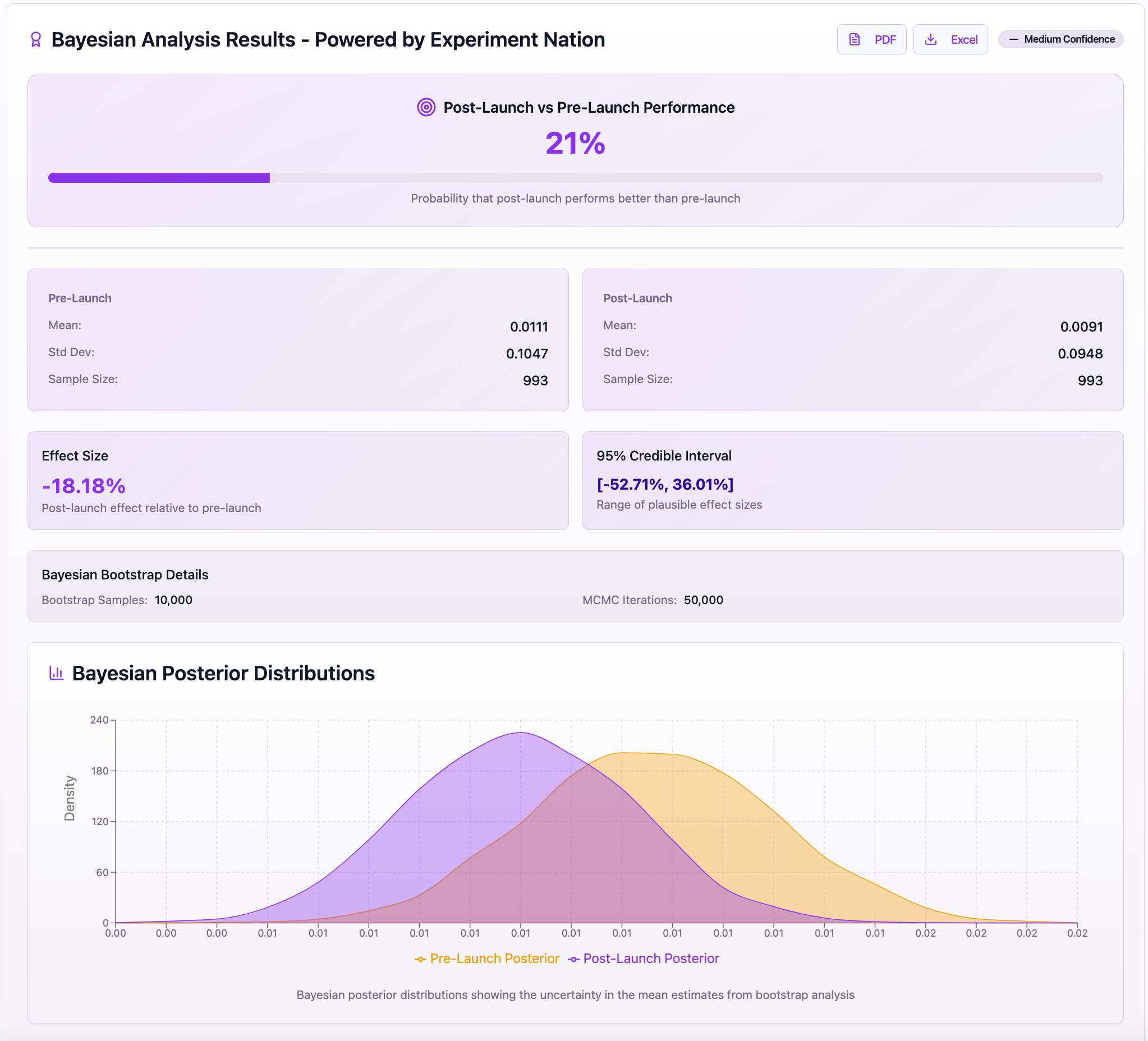
LaunchBuddy analyzes two CSVs—one pre-launch and one post-launch—each containing at least these columns:
user_id and metric_to_optimize (binary or numeric). Up to ~20k rows per file works best unless you don’t mind a bit of a wait.
The Statistics that LaunchBuddy uses to estimate impact
User-level pooling. We aggregate at the
user_idlevel so multiple events from the same user don’t skew results.Variance reduction with CUPED (when possible). If a user appears in both periods, we use their pre-period value as a covariate to reduce variance in the post-period estimate. If there’s no overlap, CUPED is skipped.
Bayesian bootstrap. We apply a nonparametric Bayesian bootstrap over users to sample a posterior for the effect (e.g., difference in means or uplift).
Clear decision metrics. We report the probability that the uplift is > 0 (i.e., the feature improved the metric) and credible intervals.
Because this is a pre- vs post-launch analysis, the analysis is still susceptible to confounds. Only a true A/B test would address things like seasonality, etc.
Your data should be as representative of your audience as practically possible.
We selected Bayesian over ANOVA because it is has no normality assumption.
Privacy Notes
You can share a link to the results for review, but the original uploaded data will no longer be available in LaunchBuddy.
Raw uploads are not stored—they’re processed locally in-session and discarded; the share link includes only aggregated summaries and charts, never your source files.
Acknowledgements
Thanks to Summer Hu (Staff Data Scientist at Meta), Khushbu Patel, PhD for their invaluable input.