FUEL: A Simpler Way for EARLY-Stage Growth Teams to Prioritize Experiments
We need to avoid Precision Theatre
If you’ve worked in growth or experimentation long enough, you’ve probably seen a lot of prioritization frameworks. Product teams often use the RICE prioritization framework. CRO teams might lean on PIE or PXL. While these frameworks can be useful, in practice I’ve noticed something: teams often end up performing what I call “precision theatre.”
Does this sound familiar?
You create a spreadsheet.
You score ideas from 1–10.
You calculate weighted scores.
And suddenly the backlog looks scientific.
But if you’re honest with yourself, most of those numbers are guesses—especially early in a growth or experimentation program. At that stage you don’t really know your biggest drivers of activation, which messaging resonates, or which parts of the product experience actually move behaviour.
The numbers make the process feel rigorous, but in reality they’re often just structured opinions.
To be clear, this isn’t unique to RICE, PIE, or PXL. Any prioritization framework that assigns numbers can fall into the same trap. Even the framework I’ll introduce in this article—FUEL—can suffer from precision theatre if teams treat the scores as exact science.
The goal isn’t to eliminate estimates. That’s impossible.
The goal is to focus the conversation on the signals that actually matter, while recognizing that prioritization is still judgment under uncertainty.
Experimentation should be about learning
Experimentation is supposed to be about learning. Every test is an attempt to answer questions about users:
What motivates them?
What confuses them?
What actually changes behaviour?
But if we’re honest, many experimentation programs end up learning surprisingly little. Teams often prioritize ideas that are easy to implement or likely to produce incremental lifts. These experiments can move a metric slightly, but they rarely deepen understanding of what truly drives behaviour. In the early stages of a growth program, reducing uncertainty is often far more valuable than squeezing out a small conversion lift. Experiments that uncover deeper insights can shape dozens of future decisions and unlock entirely new directions for growth. Yet most prioritization frameworks weren’t designed to optimize for that. They were designed to predict impact.
Many hypotheses suck
In an ideal world, prioritization frameworks wouldn’t even be necessary. If every experiment started with a well-crafted hypothesis grounded in evidence, clear expected impact, and a defined learning goal, good ideas would naturally rise to the top. But in reality, many experimentation backlogs are filled with loosely formed ideas like:
“test a new CTA”
“try a different layout”
“experiment with pricing copy”
When hypotheses aren’t structured well, prioritization becomes subjective and debates turn into opinion battles. What teams often need is a forcing function that pushes them to articulate what they expect to learn before the idea gets prioritized.
Why I created FUEL
This is what led me to create the FUEL framework.
The goal wasn’t to replace existing prioritization models like RICE, PIE, or PXL. Those frameworks can be extremely useful in the right context. Instead, FUEL is meant to complement them, particularly in earlier-stage growth programs where teams are still discovering what actually drives user behaviour.
One way to think about the difference is this:
PXL optimizes for certainty.
FUEL optimizes for reducing uncertainty.
PXL prioritizes experiments that are visible, easy to implement, and likely to produce measurable results quickly. That works extremely well when teams already understand their funnel and are optimizing known conversion levers. FUEL is designed for an earlier phase, when teams are still figuring out what actually matters.
At that stage, the goal isn’t just optimization. It’s discovery.
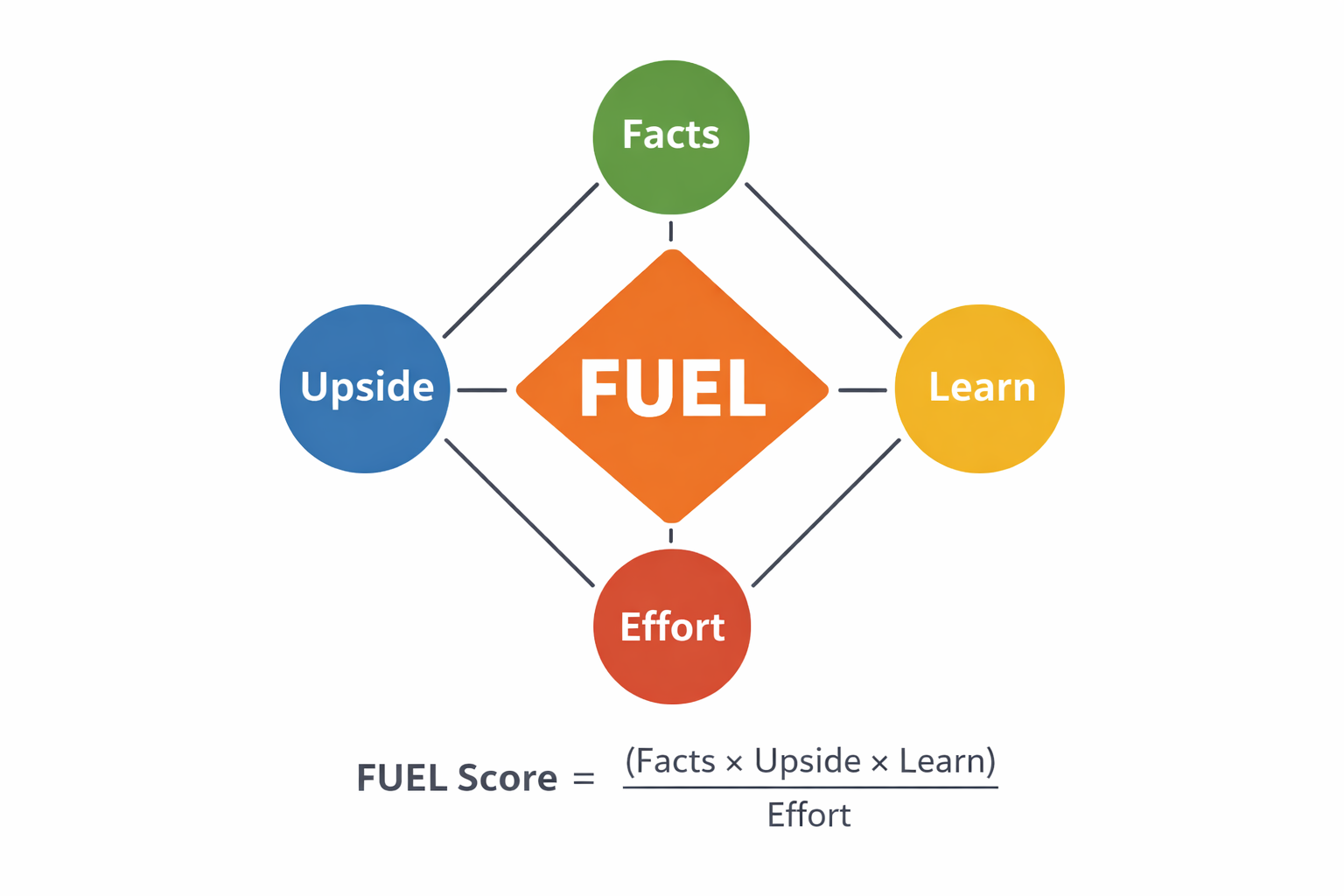
The FUEL framework
FUEL encourages teams to prioritize experiments based on four signals:
Facts
Upside
Effort
Learn
A simple way to calculate a score is:
FUEL Score = (Facts × Upside × Learn) ÷ Effort
Each factor can be scored on a 1–5 scale. The numbers don’t need to be precise. The goal is simply to structure the conversation around the signals that matter most. FUEL encourages teams to prioritize experiments based on the following:
Facts - What evidence supports this idea? Good growth ideas typically come from funnel data, session recordings, customer interviews, support tickets, or previous experiments. Example scoring:
1: Pure intuition. No supporting data or research.
2: Heuristic observation. Someone noticed something during a review or brainstorm.
3: Analytics signal. Funnel data, session recordings, or behavioral analytics suggest a problem.
4: Multiple signals. Both quantitative and qualitative evidence point to the same issue.
5: Strong validation. Research, analytics, and previous experiments all support the hypothesis.
Upside - If this works, how big could the impact be? This might mean improved activation, conversion, retention, or revenue. Example scoring:
1: Very small impact. Minor UI improvement or micro-optimization.
2: Small impact. A modest improvement to an already optimized area.
3: Moderate impact. Improvement to an important step in the funnel.
4: Large impact. Addresses a major drop-off or friction point.
5: Transformational impact. Could significantly improve activation, retention, or revenue.
Effort - How hard will this be to run? This includes engineering time, design work, analytics setup, and operational complexity. Example scoring:
1: Very easy. Simple copy or UI change.
2: Easy. Minor front-end change.
3: Moderate. Requires coordination across teams.
4: Hard. Significant design and engineering work.
5: Very hard. Large product change or multi-team effort.
Learn - What will we learn from running this experiment? In experimentation programs, win rates are often 10–20%. Most tests won’t “win,” but they can still generate valuable insight. Learning is how experimentation programs compound over time. Example scoring:
1: Little learning. Outcome won’t change future decisions.
2: Minor insight. Small tactical improvement.
3: Useful learning. Clarifies a hypothesis about user behavior.
4: Strategic learning. Tests an important assumption about the product or funnel.
5: Breakthrough insight. Could fundamentally change how the team understands the user journey.
FUEL in action
Imagine a SaaS company where only 32% of trial users reach their first “aha moment.”
Two experiment ideas emerge.
Idea A: Change the color and placement of the primary CTA on the signup page.
Idea B: Redesign onboarding to guide users toward completing their first key action.
Evaluating the 2 ideas:
Idea A:
Facts = 3
Upside = 2
Learn = 1
Effort = 1
Score = 6
Idea B:
Facts = 3
Upside = 5
Learn = 5
Effort = 5
Score = 15
The onboarding experiment requires more effort but ranks higher because it addresses a core activation problem and generates deeper insight.
How this compares to PXL
If we score the same ideas using the PXL framework, the outcome might look different. PXL uses a checklist of binary criteria, such as:
supported by analytics or research
visible to users
affects high-traffic pages
easy to implement
Because the signup page receives high traffic and the CTA test is easy to implement, the button experiment might score slightly higher under PXL. And that’s not a flaw. PXL was designed for mature CRO programs running many smaller UI experiments quickly.
In those environments:
visibility matters
traffic matters
implementation speed matters
FUEL simply optimizes for a different problem. Where PXL helps teams prioritize optimization opportunities, FUEL helps teams prioritize learning opportunities.
Why this matters
When teams over-index on scoring frameworks, they sometimes slow themselves down. Discussions become debates about whether an idea should score a 7 or an 8. That’s precision theatre.
What really matters is whether you’re learning about your customers and product faster than you were last quarter. Using FUEL doesn’t mean abandoning rigor. Teams can still estimate uplift, model impact, or size opportunities as precisely as they want.
The point is simply to recognize that most of those numbers are still estimates, especially early in a growth program. Progress beats precision theatre.
And learning compounds faster than perfectly scored spreadsheets.
TL;DR
In simple terms, PXL (and similar frameworks) and FUEL optimize for different moments in an experimentation program. PXL optimizes for certainty. It works best when teams already understand their funnel and are running many relatively simple UI experiments where traffic, visibility, and implementation speed matter.
FUEL optimizes for reducing uncertainty. It works best earlier in a growth program when teams are still discovering what actually drives user behaviour and need to prioritize experiments that generate meaningful learning. In practice, the two approaches are complementary: use FUEL to discover the levers that matter, and use PXL to systematically optimize them once they’re known.
Curious what you think
This is something I’ve been thinking about quite a bit lately while working with growth and experimentation teams. CRO and growth practitioners often emphasize that experimentation is about learning, yet the prioritization frameworks they use rarely enforce it.
FUEL is an attempt to address that.
I’d love to hear how others approach prioritization. How does your team decide what to test next?